Portfolio item number 1
Short description of portfolio item number 1

Short description of portfolio item number 1
Short description of portfolio item number 2
Published in 5th Conference on Artificial Intelligence and Theorem Proving (AITP), 2020
Paper link
Published in The Nineth International Conference on Learning Representations (ICLR), 2021
Paper link
Published in 6th Conference on Artificial Intelligence and Theorem Proving (AITP), 2021
We introduce an environment that allows interaction with an Is- abelle server in an incremental manner. With this environment, we mined the Isabelle standard library and the Archive of Formal Proofs (AFP) and extracted 183K lemmas and theorems. We built language models on this large corpus and showed their effectiveness in proving AFP theorems.
Paper link
Published in Bayesian Deep Learning Workshop at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPs), 2021
Paper link
Published in Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS), 2022

Paper link
Published in Thirty-sixth Conference on Neural Information Processing Systems (NeurIPS), 2022
![]()
Paper link
Published in arxiv, 2023
What Christian had | What I heard
— Albert Jiang (@AlbertQJiang) March 9, 2023
in mind when he |
suggested the name | https://t.co/Ac7RExnCV9 pic.twitter.com/sVIMiKRafI
Paper link
Published in The Eleventh International Conference on Learning Representations (ICLR) (Oral), 2023
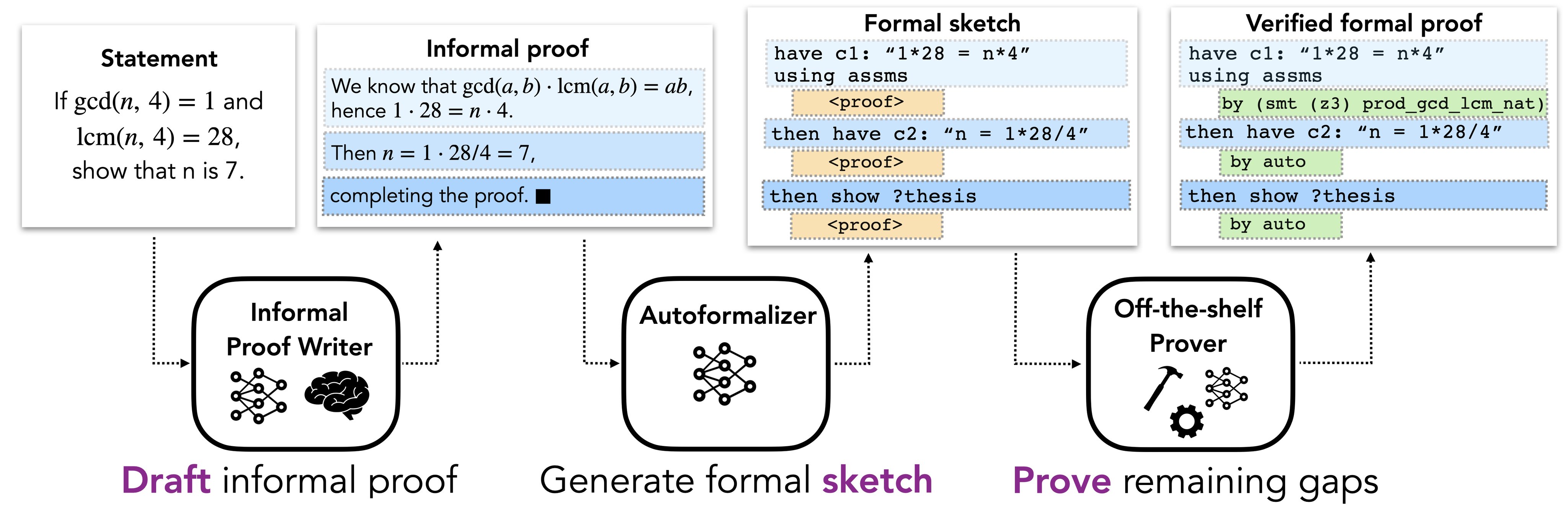
Paper link
Published in arXiv, 2023
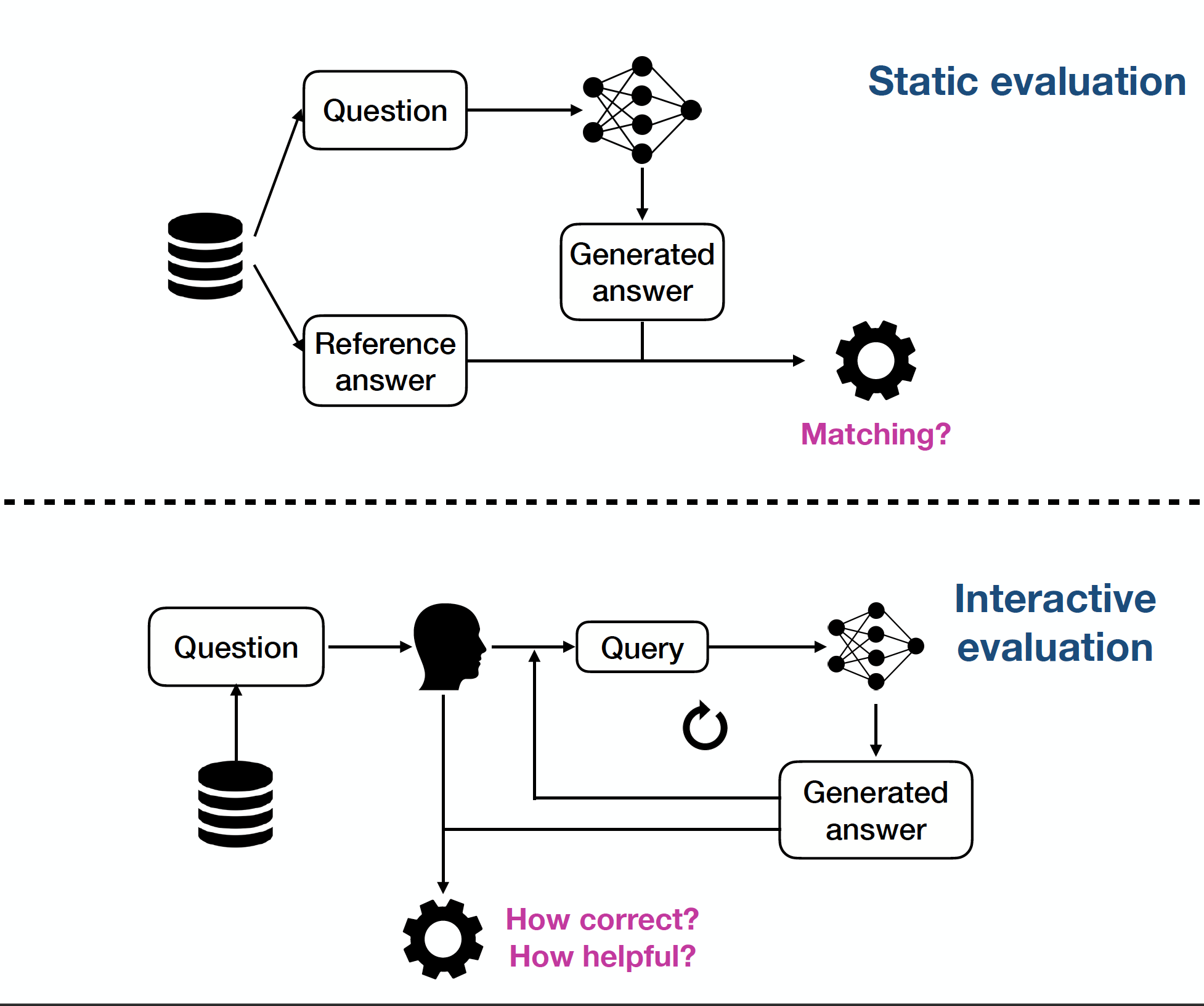
Paper link
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.
Published:
This is my first NeurIPS - last year I had three papers and no visa.
Published:
I’ve recently defended my PhD, which is on AI for formal mathematics. Now I’m a full-time researcher at Mistral AI, working on reasoning.
Published:
I find myself constantly wandering in bookshops looking for new poems and poets, often without any success.
Published:
Why am I doing formal maths/coding now.